|
显式正则化的作用。如果模型架构本身不是一个足够的正则化矩阵,它仍然能够展示出显式正则化在多大程度上有帮助。 我们论证了,正则化的显式形式,如权重削减、丢失和数据增加,都不能充分解释神经网络的泛化误差。 换句话说: 显式正则化可以提高泛化性能,但是既不必要也不足以控制泛化误差。 有限样本表达率。 我们用理论结果补充了我们的实证观察结果,表明一般大规模的神经网络可以表示训练数据的任何标记。 更正式地,我们展示了一个非常简单的双层ReLU网络,其中p = 2n + d个参数,可以表示d维中任何大小为n的样本的任何标记。 由于此前Livni et al。 (2014)使用多得多的参数,即O(dn),实现了类似的结果。 虽然我们的depth 2网络不可避免地具有大的宽度,但是我们仍然可以得到深度k网络,其中每层仅具有O(n / k)个参数。 虽然先前的表达率结果集中在神经网络可以在整个域起到什么作用,这次我们重点关注了和有限样本相关的神经网络的表达率。 与现有的对函数空间的深度层别作用认识相反(Delalleau&Bengio,2011; Eldan&Shamir,2016; Telgarsky,2016; Cohen&Shashua,2016),我们的结果表明,即使depth 2网络的线性大小已经可以表示训练数据的任何标签。 隐式正则化的作用。虽然显式正则化函数(如 dropout 和 weight-decay)对于泛化可能不是必需的,但是肯定不是所有拟合训练数据的模型都很好地泛化。 事实上,在神经网络中,我们几乎总是选择我们的模型作为随机梯度下降运行的输出。 诉诸线性模型,我们分析SGD如何作为隐式正则化函数。 对于线性模型,SGD总是收敛到具有小范数的解。 因此,算法本身隐性地使解正则化。 事实上,我们论证了,对于小数据集,即使无正则化的Gaussian kernel method也可以很好地泛化 。虽然这不解释为什么某些架构比其他架构更好地泛化,但它确实表明需要更多的研究来了解从使用SGD训练的模型中继承的属性是什么。 2.关于论证 必要的背景知识: Ademacher complexity:数据集(X_1,... X_n)上某个假设类H的复杂度度量。 平均来说,这一complexity测量了假设类H在数据中拟合所有可能的标签的机会。在下面的randomization 部分,我们将使用这种 complextiy 证明这种 complexity 不足以解释大型模型的成功。
均匀稳定性:一种显示特定模型对替换单个数据样本的敏感程度的度量。 重要的是要注意,这只是模型的属性,而不是数据本身的属性。 随机化: 第一个概念是“深层神经网络轻松拟合随机标签”。基本上,我们可以使任何组的输入拟合任何组的输出,并实现0训练错误。 这使我们得出结论,一个足够大的DNN可以简单地使用暴力记忆来拟合数据。 即使在数据中具有各种级别的随机性,该模型仍然能够拟合。随着随机化中的噪声量的增加,泛化(测试误差 - 训练误差)开始增加。这意味着模型正在学习识别什么信号应保留在数据中,并使用记忆来拟合噪声。 我们使用数据测试了几个级别的随机性,而网络总是能够在训练期间完全拟合。 然而,随着更多的随机性插入,目标函数花费了更长的时间。 这主要是由于反向传播的大误差导致了通过梯度的大规模参数更新。
图1:CIFAR10上随机标记和随机像素的拟合。(a)显示了不同实验设置下的training loss随着训练步骤恶化的情况;(b)显示了不同的label corruption ratio相应的收敛时间;(C)显示了不同的label corruptions下的测试误差(因为训练误差0,所以这同样也是泛化误差) 在这些实验中需要注意的一点是,这只是一个数据变化。 本文使用这个随机化实验来排除泛化成功的可能原因,如 Rademacher complexity 和 uniform stability。 我们可以排除complexity度量,如Rademacher,因为我们的模型完全拟合训练数据(因此,R(H)= 1)。 我们不能再使用均匀的收敛边界作为解释低泛化误差的理由。 我们也不能使用稳定性度量,因为这种改变是针对数据而不是任何模型参数。 正则化: 第二个概念是“显式正则化可以提高泛化性能,但是既不必要也不足以控制泛化误差”。 本文将正则化技术概括为有助于泛化的调整参数,但对于低测试错误不是必需的。 思考正则化的作用的一个好方法是考虑整个假说空间。 通过使用regulizer,我们实质上将可能的假设空间减小到较小的子集。 本文尝试了三种类型的显式正则化:data augmentation, weight decay and dropout。 作者发现,data augmentation和weight decay有助于减少测试误差,但即使没有使用,模型仍然能够很好地泛化。(注意:与weight decay相比,data augmentation被发现是相当有帮助的,也就是说,数据是最好的regularizer)。
表2显示了Imagenet面对真实标签和随机标签时各自的性能 作者尝试了各种形式的隐式正则化,例如early stopping和批量标准化。 对于这两种技术,泛化误差在不使用该技术的情况下只有少量减少。 这使得作者可以得出结论,“regularizer不可能是泛化的根本原因”。
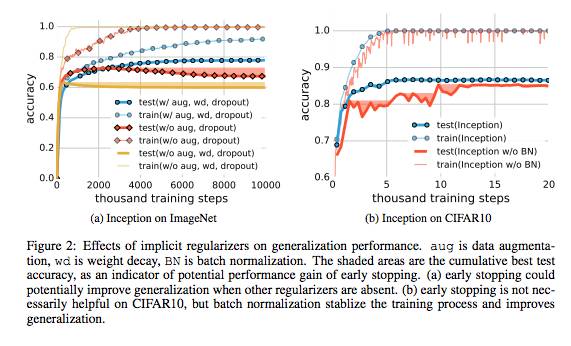
图2:隐式正则化对泛化性能的影响。aug 是data augmentation, wd 是weight decay,BN是batch normalization。(a)其他regularizer缺失时,early stopping 可以潜在地提高泛化;(b)CIFAR10上,early stopping 基本没有帮助,但batch normalization稳定了训练进程,提高了泛化。 有限样本表达率 |




 拉手网拖欠工资裁员倒
拉手网拖欠工资裁员倒 《暗黑战神》试炼之塔
《暗黑战神》试炼之塔 女子为反性侵千里徒步
女子为反性侵千里徒步
 《二十四小时》树真人
《二十四小时》树真人 人体有五个金三角!护
人体有五个金三角!护 《我不是潘金莲》:这
《我不是潘金莲》:这 2017年医保卡最全使用
2017年医保卡最全使用 2016年内地文物艺术品
2016年内地文物艺术品 湖北维和警队受表彰
湖北维和警队受表彰